
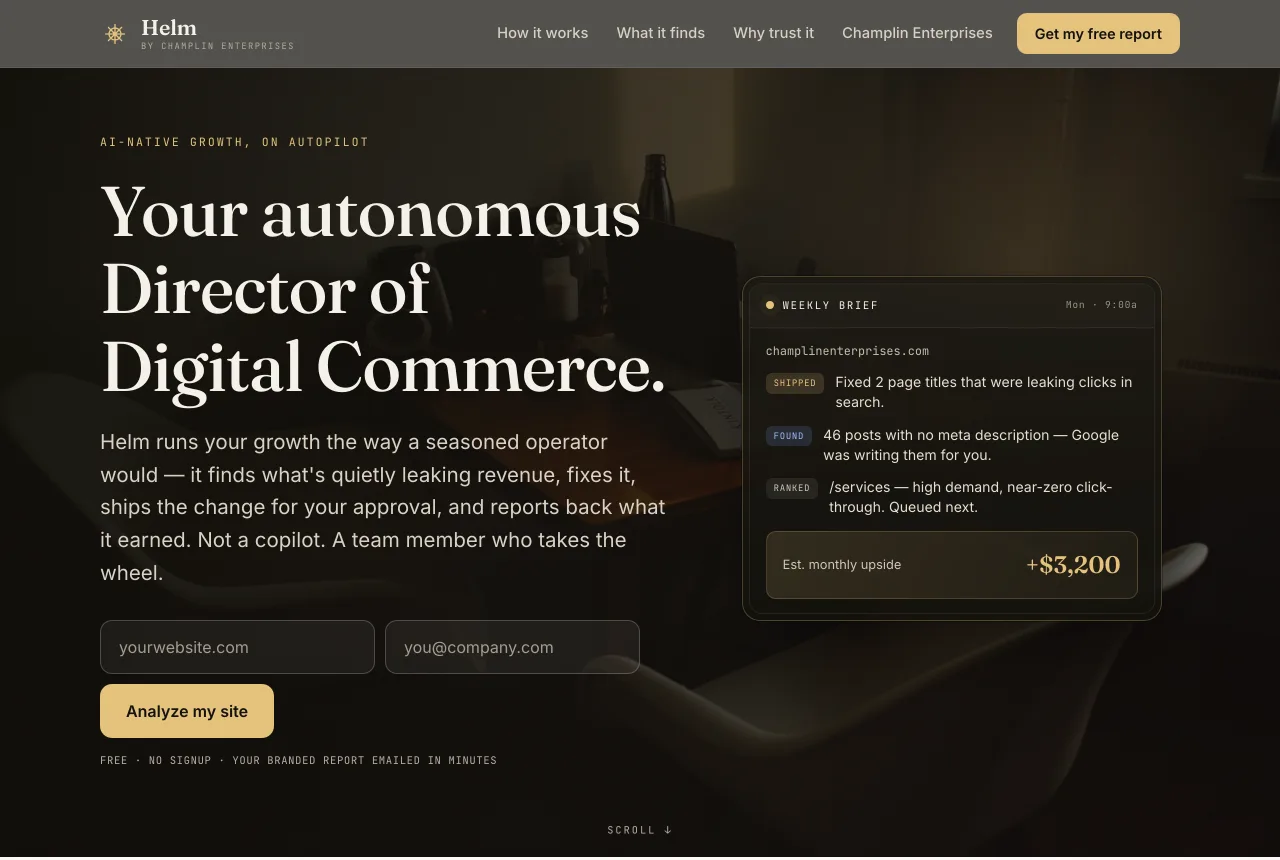
AI consulting, built to ship
AI consulting that
ships production systems.
LLM integrations, retrieval architectures, evaluation harnesses, and AI strategy from a senior engineer with 28 years of production experience. No slide decks, no workshop theater — we build the thing.
Why most AI consulting fails
Most AI consulting produces a slide deck, a workshop, and a prototype that dies on staging. The firm optimizes for billable hours, not production outcomes. Champlin Enterprises optimizes for a single metric: does the AI system work in production, measured on the cases that matter most to your business. That means evaluation harnesses before production, RAG with source attribution, and a ship-or-it-does-not-count bias.
The AI consulting engagement model
Sprint engagements start at $10,000 and typically last two to three weeks. Build engagements scale with the scope of the production system, and Fractional AI-engineering-lead retainers are available. Every engagement is led and executed by a senior engineer — no team handoffs, no juniors, no outsourcing.
The AI stack we use in production
Claude (Anthropic), GPT (OpenAI), Gemini (Google), and open-weight models (Llama, Qwen, DeepSeek). Vector stores on Pinecone, Weaviate, or Postgres with pgvector. Orchestration in TypeScript, Python, or Laravel depending on your existing infrastructure. Evaluation in Promptfoo, Langsmith, or custom harnesses. We are not locked into a single vendor or framework.
What you get
What this looks like in practice
Production LLM integrations
Grounded retrieval, structured output, tool use, and streaming. Deployed, monitored, and continuously evaluated.
RAG architecture
Your data, your answers. Zero hallucinations on source-bound queries. Built for regulated industries where provenance matters.
Evaluation harnesses
Before you ship, you know whether the AI is right on the 500 cases that matter most. Every deploy runs the eval in CI.
AI strategy and roadmapping
Where to invest, where to wait, which vendors are production-ready, and what the rollout looks like. Written analysis, not generic frameworks.
Proof of work
Products we’ve shipped
Every product below was built by one senior engineer — designed, architected, and shipped without a PM layer or an agency markup.






Trusted by
FAQ
Common questions
What AI consulting services does Champlin Enterprises offer?
Production LLM integrations, retrieval-augmented generation (RAG) architectures, fine-tuning, evaluation harnesses, intelligent workflow automation, AI strategy and roadmapping, and code audits of existing AI systems.
Which LLM providers do you work with?
Claude (Anthropic), GPT (OpenAI), Gemini (Google), and open-weight models (Llama, Qwen, DeepSeek). Provider selection is part of the engineering engagement — not an up-front assumption.
Can AI engineering produce measurable ROI?
Yes — but only when it is scoped as a production system, not a prototype. Typical measurable outcomes include decision-loop compression (days to minutes), knowledge-worker hour recovery, and triage throughput increases on tickets, contracts, or underwriting queues.
Do you help with AI strategy, or only implementation?
Both. AI strategy engagements produce a written analysis of where to invest, where to wait, and which initiatives will actually ship. They can be paired with a build-sprint option so strategy and implementation are not separated by a six-month RFP cycle.
How do you handle AI safety, accuracy, and hallucinations?
Production-grade RAG with source attribution. Evaluation harnesses that run on every deploy to catch regressions. Prompt injection defenses on user-facing interfaces. Red-teaming against known jailbreak patterns. This is the work, not an afterthought.
Is AI engineering available as a retainer?
Yes. Fractional AI-engineering-lead retainers are available — most clients start with a sprint or build engagement, then move to a retainer.
What is the minimum AI engineering engagement?
Sprint engagements start at $10,000. AI strategy sprints and code audits are commonly two to three weeks. Build engagements scale with the scope of the production system being delivered.

AI in production
Production AI.
Not slideware.

Who builds this
Kevin Champlin
Founder · Senior Software Engineer
28 years in production software — from enterprise systems to the SaaS products above. The engineer who scopes your project is the same one who builds it, deploys it, and picks up the phone after launch. No handoffs. No juniors. No telephone game.
A softer step
Not sure if you even need this kind of work?
Most businesses don't need a custom build — they need 30 minutes of real conversation to figure out whether they do. That's what the Free AI Opportunity Audit is: thirty minutes on Zoom, three concrete places AI quietly pays for itself in your business, a one-page plan emailed within 48 hours. No pitch. No follow-up sales sequence. You keep the plan whether or not we ever work together.
Three AI engagements every quarter.
A real AI problem. A real budget. A production outcome. The application takes ten minutes.
30-minute call. One-page plan emailed within 48 hours. No pitch deck.